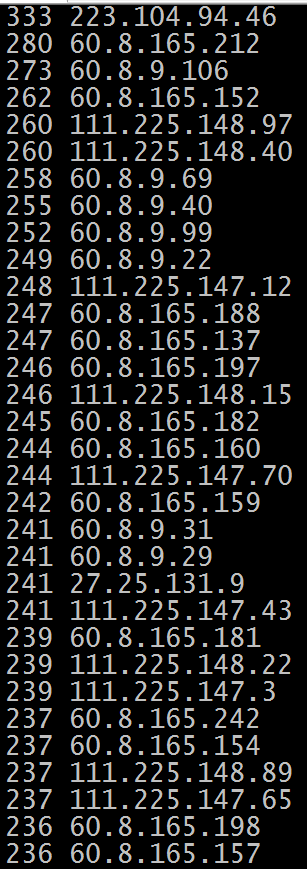
今天看面板的时候发现流量不太对,然后看了下日志发现了以下IP访问比较频繁,来自一个Bytespider的爬虫 netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' 比较有嫌疑的IP段是 60.8.9.0/24 60.8.165.0/24 111.225.0.0/24 220.243.0.0/24 直接防火墙屏蔽掉立马消停。 iptables -I INPUT -s 111.22…

服務器資源有限,受不了垃圾蜘蛛一天到晚的爬取,本配置文件適合 nginx,apache 可以自己對照著修改,IP 不斷更新中,大家可以根據自己的需要添加或刪除,由於有些來源 IP 純屬肉雞,因此僅供參考。 本文件較嚴格,基本都是一個網段一起屏蔽,如果你是企業網站、官網之類的大型站點,請斟酌。 用法: ① 下載配置文件,放到適當的位置,比如: cd /usr/local/nginx/conf/vhost/ && wget https://raw.githubusercontent.com/virclo…
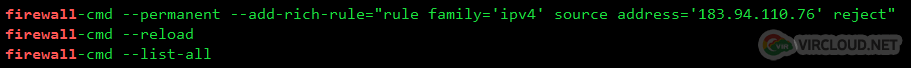
网站一般欢迎蜘蛛访问,因为蜘蛛意味着搜索排名和流量,但有时候,大量垃圾蜘蛛甚至爬虫访问很影响性能,特别是服务器配置不高的情况下,那么我们该怎样屏蔽掉垃圾蜘蛛呢? 一般来说,屏蔽蜘蛛的爬取有三种方法: Robots 禁封 UA 禁封 IP 禁封 一、Robots 禁封 Robots 协议(也称为爬虫协议、机器人协议等)的全称是 “网络爬虫排除标准”(Robots Exclusion Protocol),用来告诉搜索引擎、爬虫哪些页面可以抓取,哪些页面不能抓取。 Robots 协议在网站中体现在根目录下的 robots…